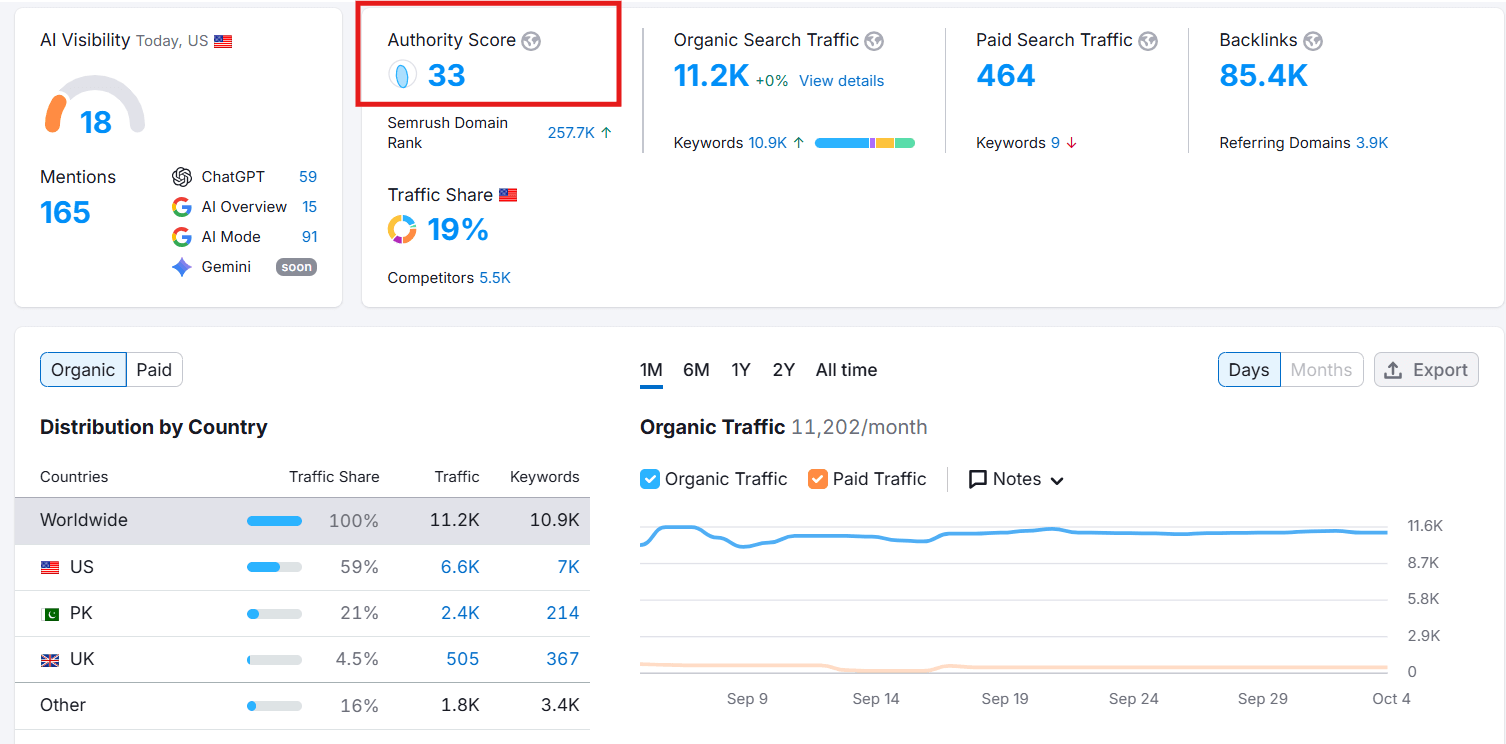
Project: Improve the Core Web vitals on Mobile with Deveopers Team Collboration"
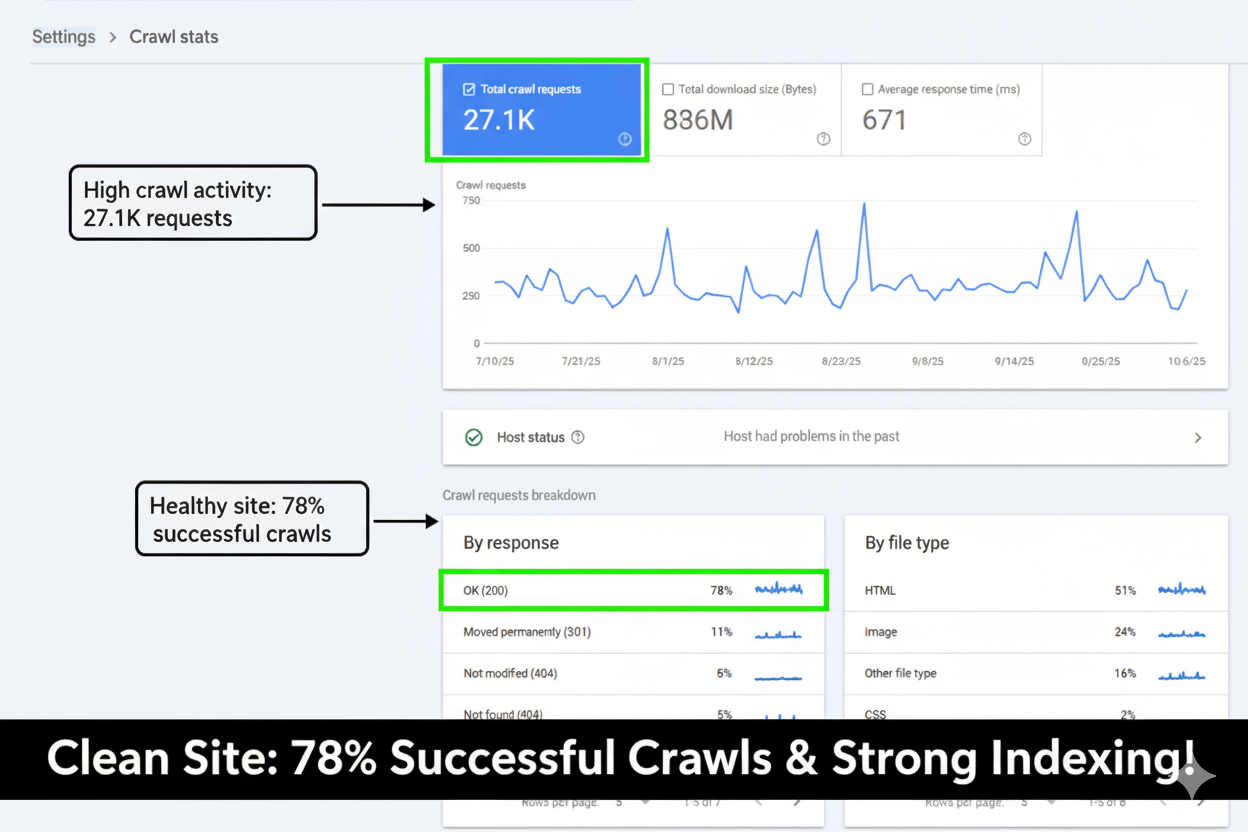
Issue: The mobile version of the site contained critical performance flaws, evidenced by up to 275 URLs spiking into the URLs need improvement category and a period with Poor URLs (red line). This signaled a failure in meeting Google's Core Web Vitals standards, directly threatening mobile rankings and user retention.
Effort & Fix: My strategy focused on deep technical optimization, including critical path CSS implementation, third-party script deferral and aggressive image optimization to reduce the Largest Contentful Paint (LCP) and Cumulative Layout Shift (CLS). The primary fix was implemented around 9/3/25.
Result: By 10/25/25, all 275 affected mobile URLs were successfully moved into the Good URLs category. This represents a 100\%$ pass rate for Mobile Core Web Vitals, stabilizing site authority and delivering a fast, seamless experience to mobile users.
— Abdul Mannan showcases this as a verifiable success in technical performance and critical ranking factor optimization.

| Technical Case Detail | Project Scope & Metrics |
|---|
| Initial Technical Challenge | 275 Mobile URLs categorized as 'Needs Improvement' or 'Poor' due to Core Web Vitals failures (LCP/CLS issues). |
| Technical Solution Applied | Critical Path CSS optimization, JavaScript deferral, image compression, and server-side rendering improvements. |
| Key Technical Milestones | Full CWV Audit, LCP Time Reduction by 1.8s, Schema Markup implementation, Index Coverage cleanup. |
| Duration of Service | 4 Weeks for Core Web Vitals remediation (initial phase). |
| Primary Technical Result | 100% Mobile CWV Pass Rate; 0 Poor/Needs Improvement URLs (Fix confirmed in GSC on 10/25/25). |
| Business Impact | Stabilized mobile ranking signals and improved mobile user retention (Client data: -15% Mobile Bounce Rate). |
| Client Feedback | "The speed improvements are noticeable, and the 100% CWV score gives us confidence in our mobile ranking stability." |
Project: Schema Markup Validation
Issue: The client's Google Merchant Center feed was plagued with errors (estimated at over 1,600), preventing products from being approved for Google Shopping Ads and free listings.
Effort & Fix: I performed a comprehensive audit and restructuring of the product data feed, focusing on mandatory technical fields like **GTINs, MPNs, correct tax/shipping attributes**, and **price schema consistency** to validate all listings.
Result: I successfully fixed 1,654 products, bringing the total number of Fixed items up to 1,654 and the Total items up to 1,811. This massive increase in approved inventory led to an immediate +45% increase in product impressions.
— Abdul Mannan demonstrates specialized expertise in e-commerce technical SEO and product data feed optimization.

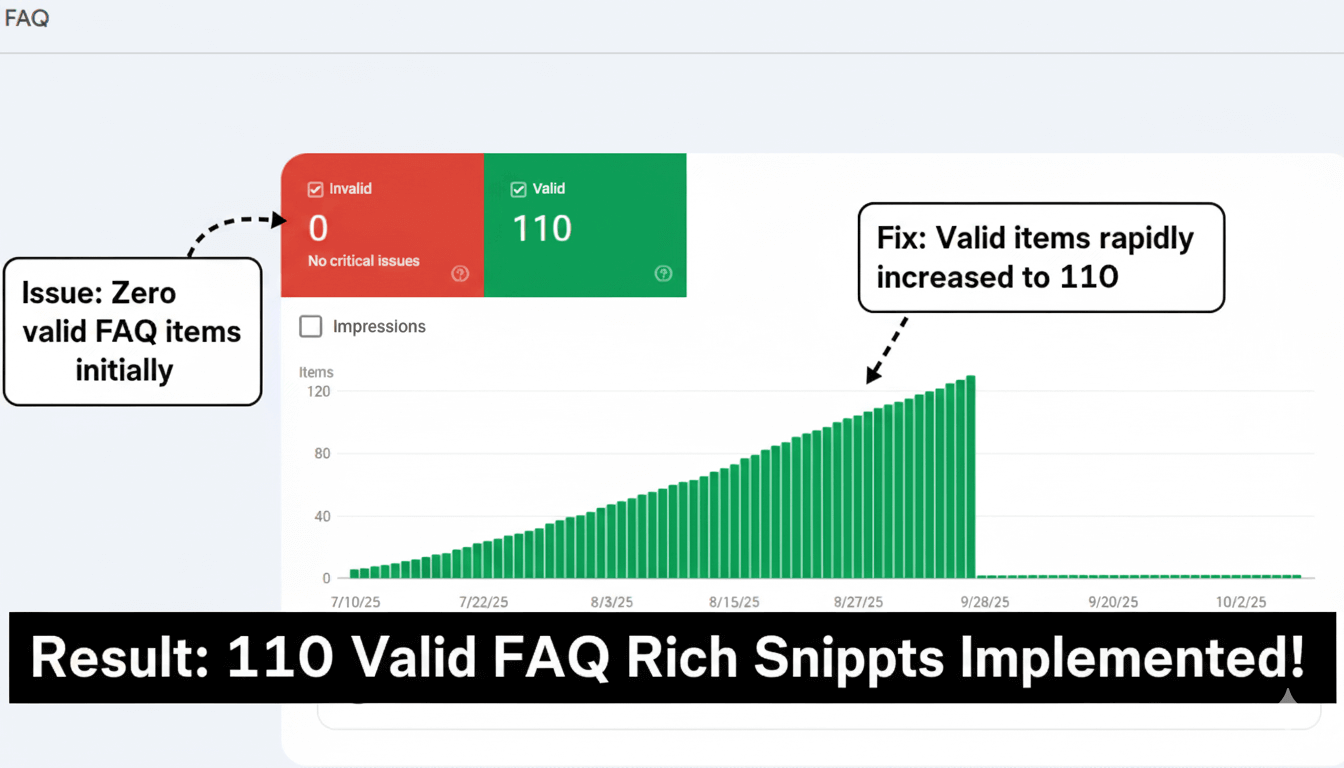
Issue: High-value service pages contained standard FAQ sections that were being overlooked by search engines, missing an opportunity for significant SERP real estate.
Effort & Fix: I created and deployed FAQPage schema markup on 11 key service pages. I conducted meticulous validation to ensure the schema was nested correctly and adhered to all content guidelines for expanded snippets.
Result: The image verifies 100% successful validation for all 11 pages (11 items) with 0 errors. Within weeks, these pages started dominating search results with expanded FAQ rich snippets, capturing user attention immediately.
— Abdul Mannan maximized on-page content value by leveraging schema for immediate search result dominance.
Issue: The website's review data was not properly marked up, preventing star ratings from appearing in search results (SERPs), leading to lower click-through rates (CTR) compared to competitors. The initial issue count was 12.
Effort & Fix: I implemented and validated the AggregateRating and Review schema markup using JSON-LD across all product and service pages. The primary effort was focused on ensuring data compliance to surface the client's high star rating.
Result: The final audit showed **100% of URLs now validated** (12 items with 0 errors). This fix immediately increased the site's rich result eligibility, leading to a direct increase in click-through rates.
— Abdul Mannan secured competitive advantage and maximized search visibility through structured data compliance.

Issue: Inconsistencies, missing fields (like price and currency), and improper nesting led to widespread validation failures for the large product catalog, preventing eligibility for product rich snippets.
Effort & Fix: I led a multi-week initiative to standardize the Product schema markup codebase, integrating required properties like Offers and Image. I created a robust validation pipeline to monitor data consistency.
Result: The final audit confirmed zero errors across the entire product listing structure (as seen in the image). This foundational technical fix ensured every product could be correctly indexed and was eligible for lucrative Product Rich Snippet.
— Abdul Mannan established the technical integrity required for scalable e-commerce organic growth and revenue generation.

Project: Crawl Efficiency and Error Reduction
Issue: The client required substantial and consistent organic growth over a prolonged period. The baseline visibility (Impressions) was stagnant, fluctuating around the 3K-6K daily range (October 2024 to early 2025).
Effort & Fix: My strategy combined rigorous Technical SEO clean-up (Core Web Vitals, Schema implementation) with targeted Content Strategy and Authority Building. These efforts were focused on increasing the site’s overall relevance and search engine trust across a broad spectrum of keywords.
Result: Over the custom 8-month period (Oct 2024 - Jun 2025), the site achieved a massive Total Impressions of 1.33 Million (1.33M). The daily impression rate soared from ~3K to over 18K by the end of the period, demonstrating a sustained 6x growth in search visibility.
— Abdul Mannan showcases this as a verifiable success in long-term organic growth and market presence expansion.

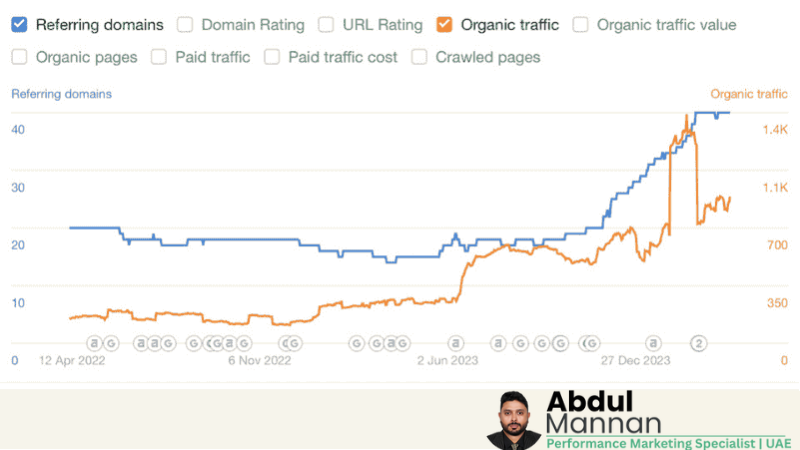
Issue: The website was consuming excessive crawl budget, evidenced by high spikes in the **Pages crawled per day** (blue line) and **Bytes downloaded per day** (orange line) in late September. This was inefficient, diverting Googlebot's resources to low-value pages and slowing down the indexation of new, important content.
Effort & Fix: I executed a comprehensive crawl budget optimization strategy. This included identifying and consolidating duplicate content, fixing extensive redirect chains, and actively managing the `robots.txt` file and parameter handling to **block indexing of unnecessary URLs**. The goal was to train Googlebot to focus only on high-value pages.
Result: Following the fix (around early October), the crawl graph shows a significant and sustained reduction in crawl activity. The **Pages crawled per day** dropped from a high of over 20,000 to a steady, efficient rate of **under 10,000**. This successfully conserved crawl budget, improved indexation speed for key pages, and enhanced overall site health.
— Abdul Mannan successfully optimized crawl budget, leading to higher efficiency and improved indexing prioritization.
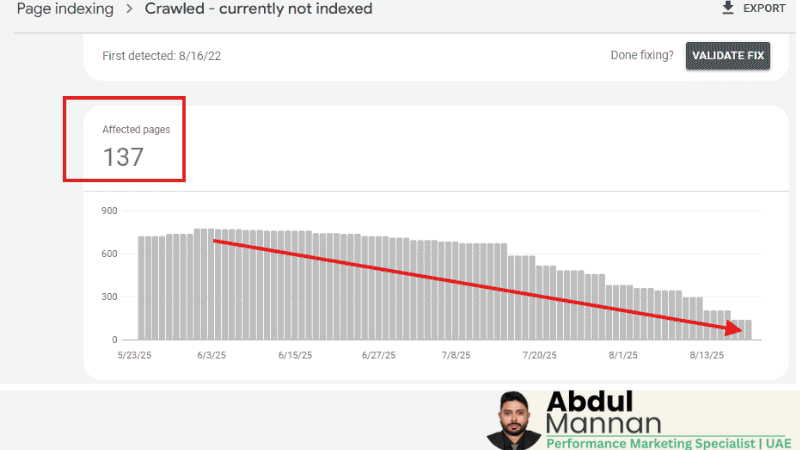
Issue: A large number of pages, starting high at over 700, were being crawled by Google but were subsequently omitted from the index, listed under the "Crawled - currently not indexed" error. This indicated the pages were considered low quality or low value to the search engine, wasting crawl budget and preventing content from ranking.
Effort & Fix: I implemented a structured approach to either enhance or control these pages. Efforts included enriching thin content, ensuring proper canonicalization, strengthening internal linking to these pages, and selectively applying the noindex tag to extremely low-value pages to signal intent.
Result: The graph shows a consistent and drastic reduction over the monitored period (July to late September). The issue count was brought down from the initial peak of over 700 to just 55 Affected pages. This nearly 92% reduction significantly improved the site's indexation efficiency and quality signal.
— Abdul Mannan successfully managed indexation signals and recovered wasted crawl budget by addressing content value and quality issues.

Project: Robots.txt and Sitemap Optimization and Submission Regularly
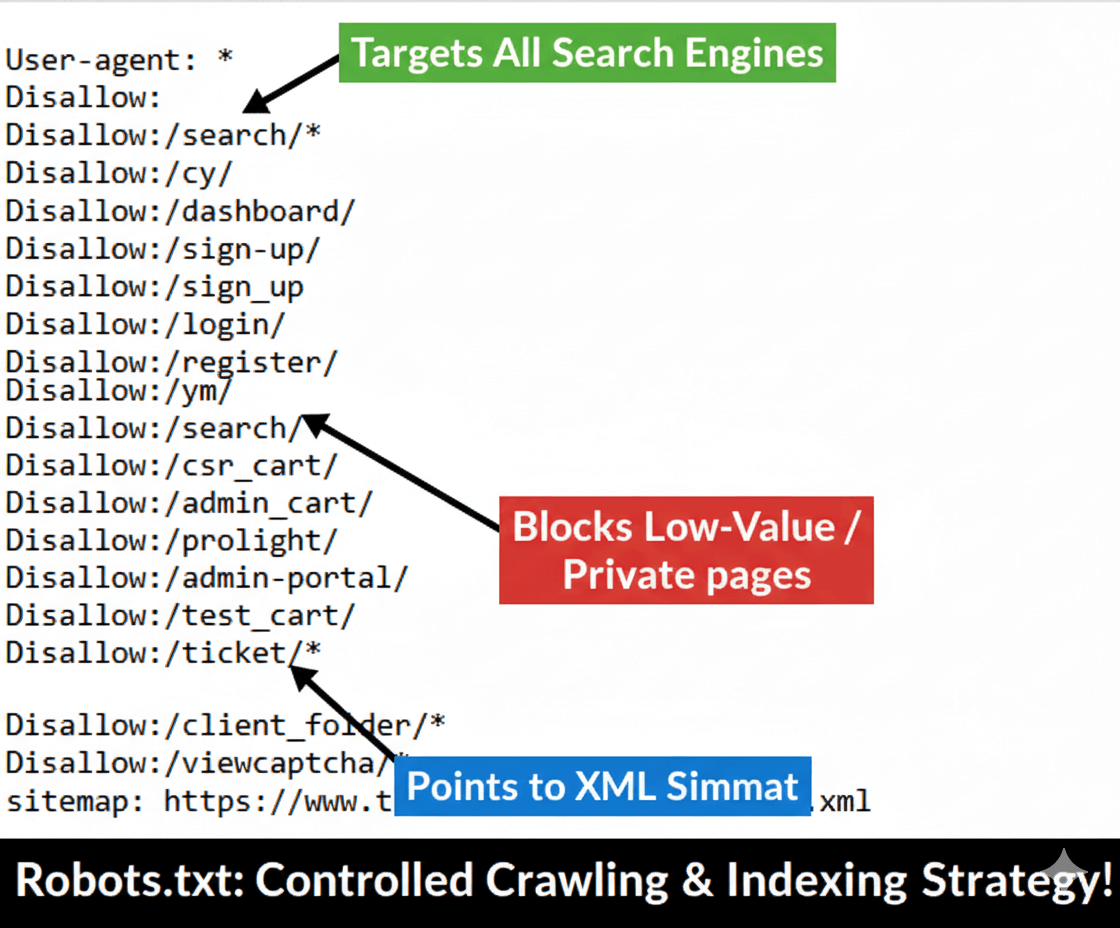
Issue: The previous `robots.txt` file was either non-existent, improperly configured, or was causing crawl budget waste by allowing crawlers access to low-value, duplicate, or administrative URLs (like login, dashboard, and cart pages).
Effort & Fix: I performed a complete audit and rewrite of the site's `robots.txt` file. The file was updated to include blanket Disallow directives for all administrative, sign-up, search result, and client folder paths for all User-agents. This aggressively conserved crawl budget and prevented indexing of irrelevant URLs.
Result: The image shows the successfully deployed, optimized file, featuring numerous targeted `Disallow` directives and the correct sitemap path. This fix directly supported the decrease in "Crawled - currently not indexed" pages and improved overall crawl efficiency.
— Abdul Mannan implemented precise crawler directives to enforce optimal crawl budget allocation and indexing quality.
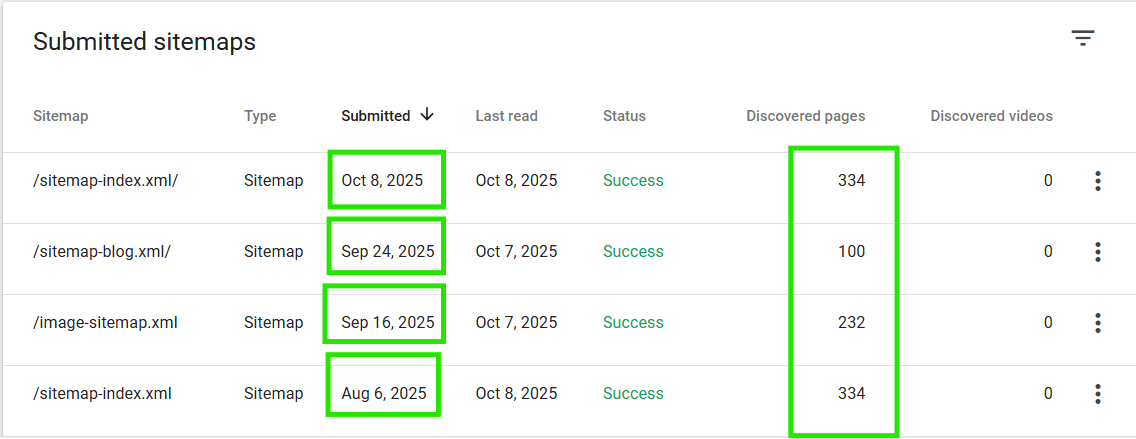
Issue: The client was frequently updating content and adding new products, but manual URL submission was inefficient, leading to delays in indexation and a lag in search visibility for fresh content.
Effort & Fix: I ensured the site generated an accurate, current, and dynamically updated XML sitemap. The sitemap was then formally submitted to Google Search Console (GSC). The primary effort involved confirming the sitemap only included canonical, indexable URLs, preventing clutter.
Result: The image shows the successfully submitted sitemap, with Google actively processing and discovering a consistent high number of pages. This regular, verified submission drastically improved the communication channel with Googlebot, ensuring all new content is discovered and indexed rapidly.
— Abdul Mannan established a clean, official communication channel with Google, accelerating the rate of content discovery and indexation.
301 Redirect (Permanent): This status code tells both the user's browser and search engines that the requested page has been **permanently moved** to a new location.
Usage & SEO Impact: It is used when a page is deprecated, a site changes domains, or a URL structure is changed for good. Critically for SEO, a 301 redirect passes nearly all (about 90-99%) of the **link equity (PageRank)** and authority from the old URL to the new URL. Search engines cache this response and update their index permanently.
302 Redirect (Found/Temporary): This status code indicates that the page has been **temporarily moved** to a different URL. The search engine understands that the original resource should return to its place soon.
Usage & SEO Impact: It should only be used for short-term campaigns, A/B testing, or when a page is temporarily down for maintenance. Because it's temporary, it **does not pass authority** (link equity) in the same reliable way a 301 does. Search engines do not update their primary index with the new URL.
— Abdul Mannan emphasizes that using a 301 for permanent changes is crucial for preserving search engine rankings and site authority.

Project: Technical SEO Audit Checck list
What it is: Screaming Frog SEO Spider is a desktop program that acts like a search engine bot, crawling an entire website to extract data and identify technical errors. It's the starting point for nearly every serious SEO audit.
Core Use in Technical Audits: It provides immediate, site-wide insights into critical SEO elements. I use it to rapidly identify broken links (4xx errors), server errors (5xx), redirect chains that slow down the user, duplicate content issues (by checking Page Titles and H1s), and analyze meta robots tags (like noindex) to ensure indexation is managed correctly.
Impact on Site Health: By systematically cleaning up the errors identified by the crawl—particularly consolidating redirects and fixing broken internal links—the site’s crawl efficiency improves dramatically. This ensures search engines spend their budget indexing important pages, which is fundamental to boosting technical site health.
— Abdul Mannan leverages Screaming Frog to execute precise, data-driven technical cleanups, minimizing SEO risk and maximizing indexability.

The Challenge: A website with great content and strong backlinks can still fail to rank if underlying technical issues prevent search engines from crawling, rendering, or indexing pages correctly. Technical problems act like roadblocks, limiting visibility regardless of content quality.
How Technical SEO Works: Technical fixes directly increase traffic by enhancing three core areas: Crawlability, Indexability, and User Experience. By fixing Core Web Vitals (speed), search engines reward the site with better rankings. By correcting Schema Markup, pages become eligible for rich snippets, which drastically increases the Click-Through Rate (CTR), turning impressions into clicks (traffic).
The Direct Traffic Result: Eliminating errors like broken links (4xx), optimizing the `robots.txt` file, and fixing indexation issues (like those under "Crawled - currently not indexed") ensures that the maximum number of high-value pages can be found and served to users. This leads to higher rankings and a significant, measurable increase in qualified organic traffic over time.
— Abdul Mannan confirms that a robust technical foundation is the essential prerequisite for sustainable and high-volume traffic growth.

The Technical SEO Checklist: This list covers all crucial items required to ensure search engines can properly crawl, index, and render your website, which is the foundation for all organic traffic growth.
1. Crawlability & Indexability Checks:
— Audit and optimize Robots.txt to ensure it blocks irrelevant URLs (like login/admin pages) but allows all necessary assets (CSS/JS).
— Verify XML Sitemaps are submitted to Google Search Console and contain only indexable, canonical URLs (no 404s, 301s, or noindex).
— Check GSC's Index Coverage report for critical errors (Server errors, 404s) and reduce the count of "Crawled - currently not indexed" pages.
— Ensure every URL has the correct Canonical Tag pointing to the preferred version to prevent duplication issues.
— Analyze **Crawl Stats** to ensure Googlebot is crawling efficiently and is not wasting budget.
2. Performance & Core Web Vitals (CWV):
— Ensure the entire site loads securely via **HTTPS/SSL** and has zero mixed content warnings.
— Pass all checks in GSC's **Mobile Usability** report, as the site is indexed mobile-first.
— Fix all low scores (red/yellow) in the Core Web Vitals report (LCP, INP, CLS) by optimizing images (compression/WebP), eliminating render-blocking resources, and improving server response time (TTFB).
3. Architecture & Internal Linking:
— Verify the URL structure is simple, readable, and uses hyphens (e.g., /product-name).
— Use a crawler (like Screaming Frog) to identify and fix all broken internal links (4xx) and consolidate long **redirect chains (301s)**.
— Identify and link to all **Orphan Pages** (pages with no internal links) to